はじめに
初めまして、fuku株式会社 代表取締役の山田です。本連載は学会の講演情報を自動で収集し、データベース化する過程の試行錯誤を公開するものです。
身近なニーズがある、個人的に関心があるなどの理由で学会の講演情報を対象としていますが、本企画の真の目的は多様かつ非構造的なテキスト情報を統一的なフォーマットに整形することができるか可能性を探ることにあります。本記事に辿り着いた方の中には論文、実験ノート、社内文書などの多様なテキストを取り扱いたいと考えている方がいらっしゃるかと思います。本企画の内容が、皆様の参考になれば幸いです。
背景・課題
発端は製薬企業の方とお話をしていた時に「学会の講演情報を調べるのが大変」と伺ったことになります。事情を深堀りしてみると以下のことが判明しました。
- 担当する疾患領域において誰が発信力を持っているか、先生同士のパワーバランス・勢力図を知りたい
- どの先生が該当疾患領域のどのような点に強みを持っているのか知りたい(e.g. 消化器症状に詳しい、患者さんとのつながりが強い、海外への発信力がある)
- これらの情報を得るために学会、論文、科研費、ガイドライン、研究班を調査する必要がある
そこで2022年5月に何件かの学会の講演情報を試しにスクレイピングしてみましたが、以下の理由で頓挫しました。
- 同じ学会の学術会議でも年度ごとにHTMLの構造が全く異なるため、すべて個別にスクレイピングコードを書く必要がある
- HTML内で情報が構造化されておらず、CSSセレクタを決めるのが大変(e.g. タイトル、講演者、所属がすべてdivタグで並列に羅列されており、クラス分けもされていない)
- 不正なHTMLの場合がある(e.g. 閉じタグがない)
個別のページから情報を抽出するコードを書くのに1~2時間かかることがザラで、とても世の中の全ての学会を対象にするのは現実的ではありませんでした。
しかし、それから時間が経ち、2022年11月にChatGPTがリリースされました。ChatGPTはわずか2ヶ月でユーザー数1億人を突破し、より高度なモデルを実装し続けています。ChatGPTの登場以来、大規模言語モデル(LLM: Large Language Model)の有用性が広く認知されており、シーンを問わず活用されています。
そして2023年9月、研究室の自動化を取り扱うLaboratory Automation Developers Conference 2023(LADEC2023)に参加するにあたって私はテーマを考えていました。その前週にバイオインフォマティクス学会で研究業界でもLLMへの関心が非常に強いことを目の当たりにし、研究 × LLMで面白いことを取り上げたいと思いを巡らせていたところ、以前断念した本プロジェクトにLLMを活用してみようと思い至りました。
問題設計
改めて今回取り組む問題について詳しく触れます。まず学会情報の多くはHTMLやPDFで公開されますが、今回はHTMLを対象とします。
HTMLからスクレイピング(情報を抽出)したいとき従来的な手法ではどうするかを簡単に解説します。例えば以下のようなHTMLを考えましょう。
<div class="session"> <p class="title">LLMを用いた学会データベースの構築</p> <p class="organizer">山田 涼太(fuku株式会社)</p> </div>
講演情報が上記のような構造で記載されている場合、タイトルは以下のように取得します。
from bs4 import Beautifulsoup html = """ <div class="session"> <p class="title">LLMを用いた学会データベースの構築</p> <p class="organizer">山田 涼太(fuku株式会社)</p> </div> """ soup = BeautifulSoup(html) title = soup.find('p', class_='title').text # LLMを用いた学会データベースの構築
さてかなりシンプルな例で示しましたが、それぞれのページで使われるHTMLタグ、階層構造、classやidは異なります。あらゆる学会から講演情報をスクレイピングするにはそれぞれのページのHTMLを理解し、個別のスクレイピングコードを書く必要があります。上記の例だけではそれほど大変に感じないかもしれませんが、実際にやってみるとイレギュラーへの対応の連発で思っていたように効率的にスクレイピングできないことにすぐに気づくでしょう。
そこで本企画ではLLMを活用することで多様なHTMLから統一的なフォーマットで講演情報を抽出することを目指します。具体的にはLLMを組み込んだシステムにHTMLを入力とし、JSON形式の講演情報が出力されることの達成がゴールです。
講演情報1つ分のHTMLから構造的な情報抽出を試みる
今回は異なる様式の短いHTMLから統一的なフォーマットで情報抽出が可能か実験を行います。
LLMを組み込んだアプリケーションを開発する際にはLangChainというフレームワークを使うと便利なのでこちらを使います。さらにLangChainには出力の型を定義するOutput parsersというモジュール群が用意されています。ここではPydanticを利用して出力の型を定義します。
from typing import List from dotenv import dotenv_values from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.output_parsers import PydanticOutputParser from pydantic import BaseModel class Organizer(BaseModel): name: str affiliation: str class Session(BaseModel): session_no: str title_ja: str title_en: str organizers: List[Organizer] class Sessions(BaseModel): sessions: List[Session] def extract(html: str, model_name: str = "gpt-3.5-turbo-16k", temperature: float = 0.0) -> dict: parser = PydanticOutputParser(pydantic_object=Sessions) prompt = PromptTemplate( template="Answer the user query.\n{format_instructions}\n{html}\n", input_variables=["html"], partial_variables={"format_instructions": parser.get_format_instructions()}, ) model = OpenAI(model_name=model_name, temperature=temperature, openai_api_key=OPENAI_API_KEY) _input = prompt.format_prompt(html=html) output = model(_input.to_string()) results = parser.parse(output).model_dump() return results
ではこの実装を用いて実際のHTMLを処理してみます。
まずは第46回日本分子生物学会年会のシンポジウムページを試してみます。画像の赤枠の部分のHTMLだけを使って試しみます。
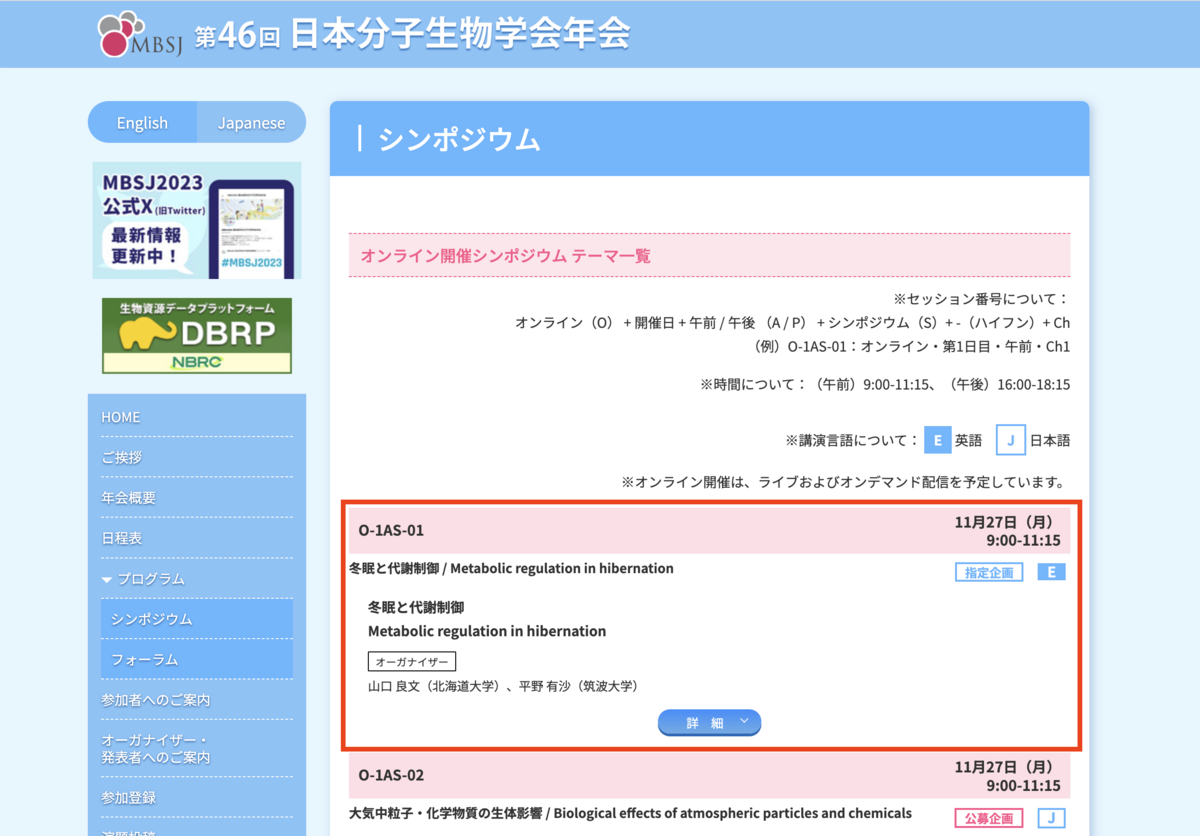
html = """ <div class="s_title_online cf"><span style="padding-top: 4px;">O-1AS-01</span> <span class="s-date">11月27日(月)<br> 9:00-11:15</span></div> <div class="kinds_box"> <div class="title_abbreviation">冬眠と代謝制御 / Metabolic regulation in hibernation</div> <div class="kinds_box_right"><span class="shitei">指定企画</span><span class="white1">E</span></div> </div> <dl> <dt>冬眠と代謝制御<br> Metabolic regulation in hibernation<br> </dt> <dd class="symposium_organizar"> <em>オーガナイザー</em><br /> 山口 良文(北海道大学)、平野 有沙(筑波大学)</dd> <dd class="center"> <div class="symposia_switch"><span>詳 細</span></div> <p class="text">冬眠は、飢餓と寒冷に見舞われる厳しい季節を低体温・低代謝の休眠状態で乗り切る生存戦略である。冬眠現象自体は古くから人々の興味を惹いてきたが、その制御機構は未だ多くの点が謎のまま残されている。近年、解析技術の進歩や休眠状態を誘導する神経細胞の発見などにより、哺乳類の冬眠現象に新しい視点で切り込むことが可能となった。本シンポジウムでは、冬眠・休眠中の動物の体で生じる代謝変化に着目した最新研究を紹介する。</p> </dd> </dl> """ extract(html)
結果は以下の通り。いい感じです!
{
'sessions': [{
'session_no': 'O-1AS-01',
'title_ja': '冬眠と代謝制御',
'title_en': 'Metabolic regulation in hibernation',
'organizers': [
{'name': '山口 良文', 'affiliation': '北海道大学'},
{'name': '平野 有沙', 'affiliation': '筑波大学'}
]
}]
}
特に感動的なのは、1つのddタグでまとめられた2名のオーガナイザーの情報をちゃんと2人分に分割したことです。従来のスクレイピングでこれをやろうと思ったら「"、"で人ごとに分割して、"("の前が人名で、"()"の中が組織で...」と結構面倒です。
<dd class="symposium_organizar"> <em>オーガナイザー</em><br /> 山口 良文(北海道大学)、平野 有沙(筑波大学)</dd> <dd class="center">
この時点でかなり感動しました。これはスクレイピングが革命的に楽になるのでは...?
ただ本当に汎用性があるのかわかりません。次はLADEC2021のconnpass募集ページを試してみます。果たして全然異なる構造のHTMLでも同様に統一的なフォーマットで抽出できるのか。
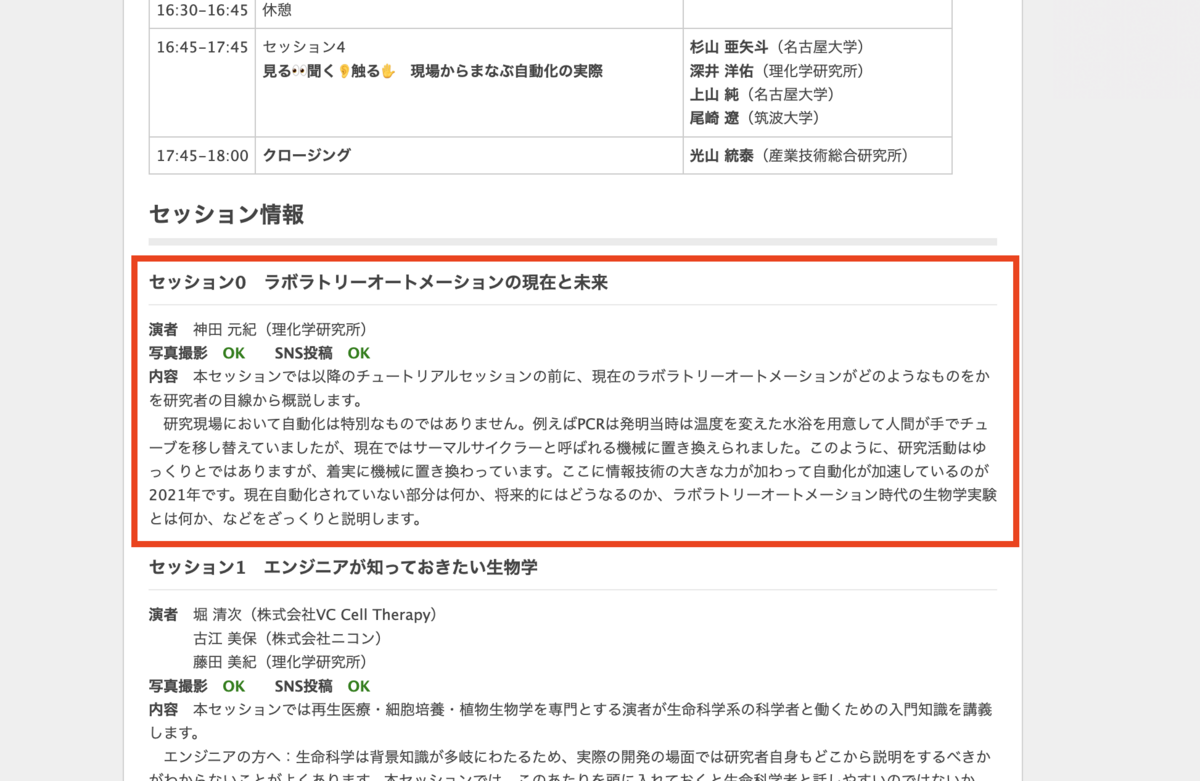
html = """ <h4>セッション0 ラボラトリーオートメーションの現在と未来</h4> <p><strong>演者</strong> 神田 元紀(理化学研究所)<br> <strong>写真撮影</strong> <span style="color: rgb(0,128,0);"><strong>OK</strong></span> <strong>SNS投稿</strong> <span style="color: rgb(0,128,0);"><strong>OK</strong></span><br> <strong>内容</strong> 本セッションでは以降のチュートリアルセッションの前に、現在のラボラトリーオートメーションがどのようなものをかを研究者の目線から概説します。<br> 研究現場において自動化は特別なものではありません。例えばPCRは発明当時は温度を変えた水浴を用意して人間が手でチューブを移し替えていましたが、現在ではサーマルサイクラーと呼ばれる機械に置き換えられました。このように、研究活動はゆっくりとではありますが、着実に機械に置き換わっています。ここに情報技術の大きな力が加わって自動化が加速しているのが2021年です。現在自動化されていない部分は何か、将来的にはどうなるのか、ラボラトリーオートメーション時代の生物学実験とは何か、などをざっくりと説明します。<br></p> """ extract(html)
なんと、気を利かせてタイトルの英訳までしてくれている...!厳密な情報を取得する場合は余計なお世話ですが、ここまでしてくれるとは想定外でした。
{
'sessions': [{
'session_no': 'セッション0',
'title_ja': 'ラボラトリーオートメーションの現在と未来',
'title_en': 'Current and Future of Laboratory Automation',
'organizers': [
{'name': '神田 元紀', 'affiliation': '理化学研究所'}
]
}]
}
そして先ほど同様、特にHTMLタグのどこに何が書かれているかを指示することもなく、適切に情報を抜き出すことができています。
ちょっとした遊びのような実験ですが、感動的です。 これもPythonでスクレイピングコード書こうと思ったら地味に大変です。例えば以下の部分だけでもため息が出ること必至です。
<p><strong>演者</strong> 神田 元紀(理化学研究所)<br>
名前の部分だけを囲ったタグがないのでpタグの中から該当部分を取得するルールを考えなくてはいけません。「strongタグは除外して、brタグまでの範囲を取得して、先頭に空白はstripで除去して、...」。想像するだけで嫌になります。 そして頑張って書いたスクレイピングコードはこのページでしか機能しないのです。割りに合いません。実際LADEC2021のページはセッションが4つしかないので手作業でコピペした方が絶対早いです。
以上、LangChainでHTMLから情報抽出を行い、Pydanticで定義したフォーマットで出力することに成功しました。 さらにコードを書き換えることなく、全く構造が異なるHTMLから統一的なフォーマットで情報を抽出することができました。
ものは試しでやってみた実験でしたが、想像以上に良い結果でした。
次回
PythonでBeautiful Soupを使って書いていた時は楽しくない上に汎用性もなく、あまりの果てしなさに絶望を感じていた講演情報のスクレイピング。しかしLangChainとPydanticを使うことで光明が見えてきました。
次回はより大きな塊のHTMLを扱うことにトライします。
最終的には、ウェブページをまるまる入力できる情報抽出システムを作ることができるのかでしょうか?乞うご期待。
宣伝
fuku株式会社は自然言語処理と研究情報の分析に強みを持った開発企業です。
論文、社内文書、実験ノート、添付文書、アンケートフォームなど幅広いフォーマットの文書を対象としたシステム開発を提供してきた実績があります。
お困りのことがございましたらぜひ以下のフォームからご相談ください。
おまけ
本記事の実験結果はLADEC2023で発表しました。